
What is JavaScript?
JavaScript is a programming language that adds interactivity to a website or program. Used along with HTML and CSS, JavaScript can add useful features and functionality to any site. Having basic knowledge of JavaScript goes hand-in-hand with technical SEO. Since JS is becoming increasingly common, as an SEO, it can be helpful to understand its features, basic qualities and how it is interpreted by Google.
Much of the relationship between JavaScript and SEO has nothing to do with the code itself, rather, it involves understanding how Google and other programs use JavaScript to process information. Learning basic JavaScript concepts can help keep SEO strategies well rounded and presents more opportunities to work with a wider range of programs and frameworks.
Here are a few helpful terms to know that may come up when researching JavaScript and SEO:
- Caching – the process of storing data and information about a site’s content.
- CDN – Content Delivery Network – helps distribute how content is loaded, by reducing loading delays and providing a stronger connection between the server and users.
- DOM – Document Object Model. The DOM allows other programs to interpret the content of an HTML or XML document that is displayed in the browser. Mozilla Developer Network has a useful article all about the DOM. The DOM is basically an organizational map.
- Googlebot – a software used by Google to crawl and index sites for search engines. There are usually separate mobile and desktop crawlers.
- Indexing – the process in which a server crawls a website
- JSON – JavaScript Object Notation represents structured data and sending information from server to server to display content on a page.
- JSON-LD – JavaScript Object Notation for Linked Data is a way of organizing and processing linked data.
- jQuery – a JavaScript library that provides succinct code and shortcuts to make JS files as concise as possible.
- Rendering – when Googlebot processes code and interprets the content in order to get an understanding of the structure of a site.
How Google Interprets JavaScript
Google uses JavaScript to process a page’s information; therefore, contributing to the website ranking on SERPs. When a page is marked to be indexed or when running a Google Lighthouse audit you see firsthand how Google utilizes JavaScript to interpret content.
The Googlebot
Googlebot crawls content and makes it indexable for search engines. When processing JavaScript, Googlebot needs to render the content before indexing. Using robots.txt can communicate with Googlebot during the rendering process to limit and block access to certain content, keeping URLs from being crawled and indexed. Make sure that Google can access all the content by “allowing” googlebot to render and process content appropriately. Within robots.txt add:
User-Agent: Googlebot
Allow: .js
Allow: .cssThis will ensure that Googlebot has the opportunity to process all the content and data necessary to render and index. Once the content has been indexed, it can start establishing a ranking. The more specific, structured and efficient the content is, the more information Googlebot has to gather for indexing.
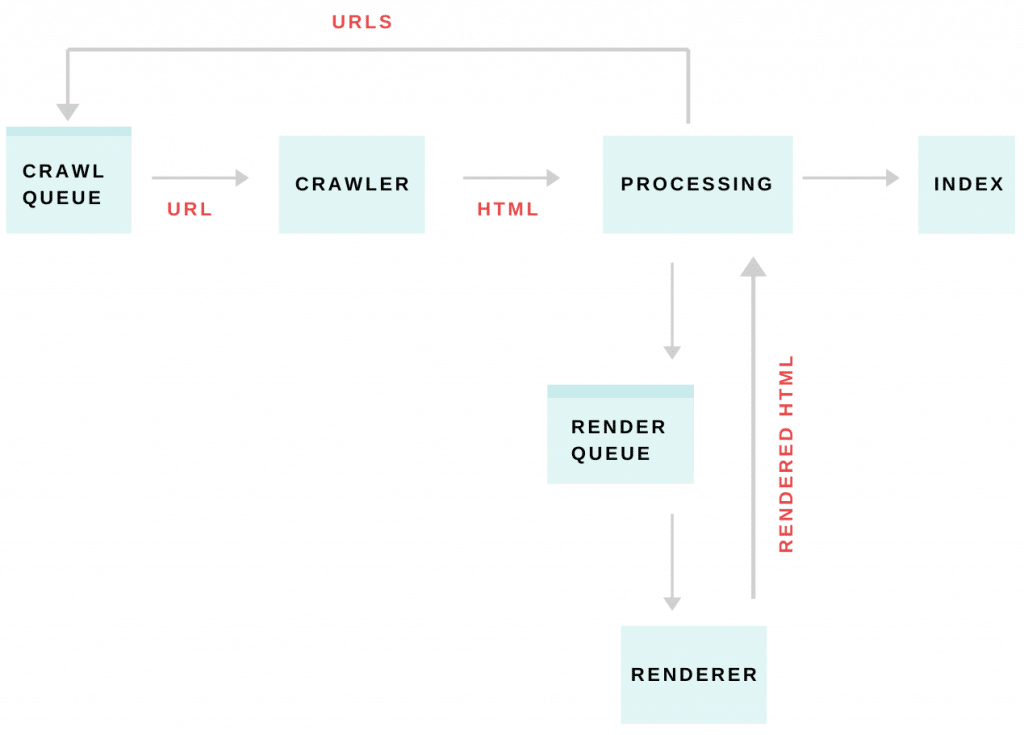
Crawling
The Googlebot will crawl both desktop and mobile versions of a website for indexable pages that can be presented to users. During the process of crawling, bots identify any errors that could interfere with the overall user experience. While the site is being crawled, JavaScript is used by Google to identify potential server errors.
Processing links
In order to establish which pages to prioritize while crawling, Google checks each page’s external and internal links. When Google understands how these links relate to the page, they are added to the crawl queue. It’s best practice to implement <link> tags for internal links and to use <a> tags with an href attribute for any external links. The <link> tags allow Google to organize those CSS and JS files in relation to the HTML it is crawling. Additionally, links that have been added using JS won’t be identified by Google until the rendering process is complete. By differentiating links with <link> and <a>, Google can easily identify the types of links and further prioritize and crawl the pages. Here are some examples from Ahrefs of how to set up the <a> tags:
<a href=“/page”>a good example</a>
<a href=“/page” onclick=”goTo(page)”>another good example</a>
It can be easy to confuse the href part of the tag with other aspects of the correct code. For example, remember to not replace href with goTo or onclick as this will not function as intended; therefore making it difficult to crawl. Here are a couple bad examples from the same Ahrefs article:
<a onclick=”goTo(‘page’)”>nope, no href</a>
<a href=”javascript:goTo(‘page’)”>nope, missing link</a>Rendering
JavaScript rendering is completed by reading and processing script tags to prepare for execution of the content in the browser. This stage is when Googlebot adds URLs to the crawl queue to be indexed, unless there is code telling Google to keep specific URLs nonindexed. This process allows Googlebot to process and understand web content as users would. Google has written a useful guide about different types of rendering. This stage is unique to JavaScript files and takes a bit longer than standard HTML files.
Indexing
When URLs reach the indexing stage, that means the page(s) have successfully been processed by Googlebot. Indexing is an important part in ensuring that the content is being crawled by Google. If pages are non-indexable, this could hurt rankings and will keep users from seeing specific content. However, there are instances in which pages are intentionally marked no-index.
Troubleshooting JS Issues
Testing tools
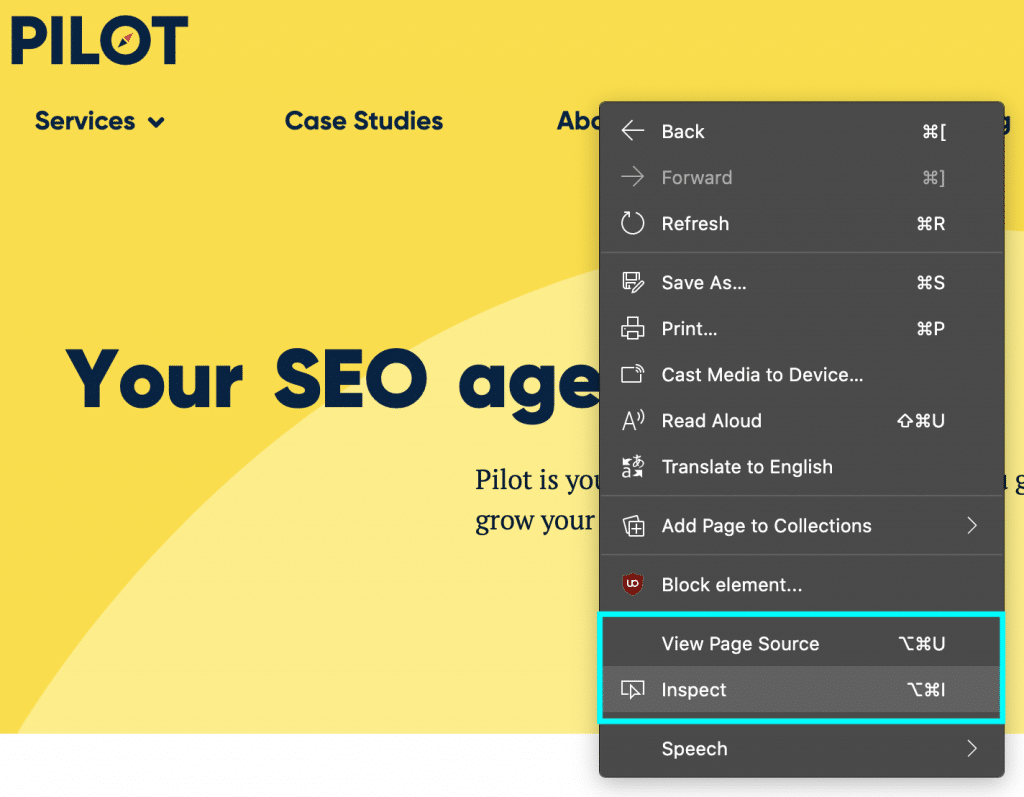
While Google is attempting to index a page, there is a possibility that Googlebot will encounter some JavaScript errors that prevent it from crawling. There are many different methods of identifying JS errors that make the troubleshooting process a lot easier. Using “view page source” when left clicking on a page will present the raw HTML, while “inspect” allows for a more updated view with the most current changes that have been made.
Another way to see potential errors is to use the URL inspector in Google Search Console as well at the Mobile-Friendly Test. Using these tools will help identify what areas of the code are slowing down the rendering process and can shine a light on issues that are being caused by JavaScript. Even though Googlebot runs JS, it cannot fix issues within the code that can keep the page and it’s content from moving on to the rendering stage.
Soft 404 errors
These errors tell users that the page they are trying to reach is unavailable and doesn’t exist. If this page is in fact unavailable to users, it’s important to set up redirects that can bring users to the appropriate page. To prevent the pages with soft 404 errors from being indexed, edit the robots meta tag to “noindex” or set up a redirect. Redirects within the JavaScript file will tell Googlebot how to react when it reaches that URL. The URL inspection tool is an easy way to identify these errors.
It’s important to keep track of all 400-level errors to make sure that these don’t end up affecting the user experience. Also, fixing 400 errors allows the content to be more easily processed by search engines. Aside from 400-level errors, using 301 and 302 redirects tell Googlebot where specific content has moved, providing a path for crawlers and users alike.
Duplicate content
Duplicate content can appear within one site or across multiple sites and interfere with the rendering process which, ultimately, hurts rankings. If another domain contains the same content as a page that is attempting to be ranked higher, it is possible that the copy can be rendered and gather ranking. Moreover, when duplicate content is present in multiple domains it is possible for the undesired URL to gain backlinks, which can confuse both crawlers and users. Having duplicate content makes it harder for crawlers to access the most updated version of a site. This can result in the speed at which pages are crawled and incorrect indexing. It’s important to note that sometimes Google will assume that some duplicate content is an attempt to manipulate rankings, at which point, they will intentionally remove the page from the index and prevent them from going through the rendering process.
How an understanding of JavaScript can transfer over to SEO
Google Tag Manager
With Google Tag Manager, it’s very easy to control when and where a custom JavaScript tag runs on your website. Add in the fact that it’s simple to implement custom variables into your JavaScript, and it’s easy to see that the combination of JavaScript and Google Tag Manager is a very powerful tool, especially for lay person who can get a little help from someone who knows how to write JavaScript.
Controlling When & Where a JavaScript Tag Runs
This is one of the most obvious strengths of Google Tag Manager; it essentially gives you the ability to fire any tag (JavaScript included) whenever you want. Here are just some of the ways you can customize when your tags fire:
- Specific URL, or a URL pattern
- Referring URL, URL pattern, or Domain
- Time on page, or time on site
- Scroll Depth
- Clicks on a given element, or set of elements
- Visibility of a given element, or set of elements
Custom Variables
With the ability to set and integrate custom variables into your JavaScript, Google Tag Manager allows you to customize your JavaScript even further. It even allows you to create some interesting automations. Take our previous post about using JavaScript with custom variables in GTM to automatically create and add BreadcrumbList schema to every page on a website. The combination of GTM, custom variables, and a custom JavaScript tag allowed us to automatically write and inject JSON-LD BreadcrumbList schema unique to each page. Most importantly, it was done in a way that still allowed Google to crawl the schema, and display the rich breadcrumbs in the SERP.
Setting up a Data Layer
It is recommended to set up a data layer to easily pass variables and events through GTM. Adding a data layer to a page involves a simple script tag that can be inserted into an HTML file, which will send data to the GTM container:
<script>
dataLayer = [];
</script>Note that this code needs to be included before the GTM snippet in the HTML. Information that is meant for Google Tag Manager is to be included within the brackets. For example, signup form buttons, unique pageviews and interactions with other links on a site. Data layers also ensure that the data and tags will remain synced if potential issues arise during processing.
Understanding the data layer, and the JavaScript it involves, make it easy for non-developers to read and interpret the code and how it relates to the goals of a business.
On-page elements
To ensure that a site’s content is being accurately represented during indexation, it’s important to implement strong basics elements across the site. When site content is being processed, elements like titles, headings and meta descriptions are analyzed in order to present the information in a way that can easily be interpreted by search engines and users. These elements work together to give a well-rounded image of a page to crawlers. The stronger these elements are, the more opportunities there will be for uses to land on the page.
Optimizing images correctly can have a positive effect on a page’s performance; however, a huge amount of large images can hurt ranking by making pages slower. Luckily, lazy-loading helps conserve data and time by only fully displaying elements once a user arrives at that section. Adding the <img loading=lazy> attribute to a JavaScript file will help distinguish between lazy-load images and others. Keep in mind, though that if lazy-loading is not implemented correctly, those images and videos it will be hidden from crawlers.
Structured data
There are many types of structured data available depending on the type of products of services offered through a site. Structured data is almost like a content outline that search engines can use to process and present information to users. Implementing structured data is considered best practice as it allows search engines to understand the content of a page.
JSON-LD is the recommended structured data format as it makes the individual data easy to read and process. Because of the emphasis on linked data, JSON-LD provides an easy trail for crawlers to navigate. JSON-LD can be implemented within an HTML file with a script tag or through embedding widgets. Here is an example of what a JSON-LD snippet for would look like in an HTML doc:
<script type=“application/ld+json”>
{
"@context": "http://www.schema.org",
"@type": "Brewery",
"name": "Chicago Brewz",
"address": {
"@type": "PostalAddress",
"streetAddress": "123 LP Ave",
"addressLocality": "Chicago",
"addressRegion": "IL",
"postalCode": "60614"
}
}
</script>Implementing JSON-LD structured data makes the page’s listing in search results more accessible and easy to find. Users can search for specific elements that are included in the structured data and get results that point to that site. Structured data can be added to an existing HTML file by using JavaScript. This can supplement structured data that is already in place or stand on its own. To ensure that everything runs smoothly, it’s important to test the code with the Rich Results Test.
Learning JavaScript
JavaScript Courses
Compared to other backend web development languages like C++ and Python, JavaScript is fairly easy to learn. There are many resources online to learn JavaScript for free, and others that cost a monthly fee, at least. Below is a list of a few programs and their costs.
- freeCodeCamp.org – Free
- Learn JavaScript – Free
- Codecademy – The Basic plan is free and they offer a Pro plan for $19.99/month
- Watch and Code – Free Practical JavaScript course and they also have a Premium Membership for $49/month.
- Pluralsight – 10-day free trial, then plans start at $29/month
JavaScript is a complex web development language that can contribute to the success of a website and help guide SEO strategies. When learning JavaScript, try to come up with a short list of goals, as to not get off track when the courses get difficult. Remember that you can always switch gears and pursue other resources that can give you an understanding of basic JavaScript concepts that can supplement your SEO knowledge.
Learning JavaScript without a course
Not all JavaScript knowledge is confined to taking a course. Many JavaScript concepts can be learned by practicing effective SEO strategies.
Running a Google Lighthouse Audit is a good, basic introduction to JavaScript as some of the improvement suggestions involved editing JS files. For example, when running a site speed test, you may come across suggestions to “remove render-blocking content.” This can consist of any code that is interfering with the bots path to reach the JavaScript and HTML code within the pages. This can be fixed by removing any code that isn’t being utilized as well as unnecessary comments or whitespace in the code.
Ultimately, as JavaScript is becoming more integrated with commonly-used frameworks and general SEO practices, there are many opportunities to gain an understanding of the language. Whether it’s learning a course of picking up techniques from other practice areas, JavaScript knowledge can only be beneficial in the long run.


